【Python】Scrapyを利用してスクレイピングに入門してみた
ご無沙汰しております!激ヤバ引っ越し作業と土日のイベントでなかなか記事が書けておりませんでした。
引っ越しも落ち着いてきたので、またチマチマ投稿していこうと思います。
本日はPythonのスクレイピングフレームワークであるScrapyを使用し、人生で初めてスクレイピングに挑戦してみたので、その模様をお届けしたいと思います。
言葉は聞いたことがあるスクレイピング、wktkです。(もう死語かもしれない)
作業概要
まずは簡単に今回の作業概要を順序立てて説明しておきます。(使用OSはMacです)
今回スクレイピングするのはyahoo星座占いです。僕は天秤座なので天秤座の総合運点数をスクレイピングして撮ってきましょう。
https://fortune.yahoo.co.jp/12astro/libra
順番としてはこんな感じ
– scrapyのインストール
– scrapy新規プロジェクト作成
– spider(クローラ)の設定
– レッツスクレイピング
早速順番に取り掛かっていきましょう。
scrapyのインストール
まずは今回の主役、scrapyをインストールします。
今回はpipでインストールするのでコマンド一つです!
$ pip install scrapyインストール確認がてらバージョンも見ておきましょう。
$ scrapy version
Scrapy 2.6.1バージョンが確認できたらインストールは無事完了しています。次にいきましょう。
新規プロジェクト作成
次に、新規プロジェクトを作成します。これもコマンド一つです。
$ scrapy startproject uranai プロジェクト名に少々投げやり感がありますが、今回は"uranai"でいきたいと思います。
こんな感じの構造でファイルが出来上がるかと思います。
.
├── scrapy.cfg
└── uranai
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-310.pyc
│ ├── items.cpython-310.pyc
│ └── settings.cpython-310.pyc
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-310.pyc
│ └── scrapy_uranai.cpython-310.pyc
└── scrapy_uranai.pyこれでプロジェクトの作成も完了です!次にいきましょう。
spider(クローラ)の設定
まずはスクレイピングで取得した要素を格納するフィールドを用意しておきましょう。
フレームワーク中のitems.pyにて用意できます。UranaiItemというアイテムの中にフィールドを作成していきます。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class UranaiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
total_point = scrapy.Field()
pass今回は総合運を取得してくるのでtotal_pointというフィールドを用意しておきましょう。これで、取得した総合運はtotal_pointというフィールド名とセットで出力されます。
次にSpiderの準備をしていきます。実際にスクレイピングする対象など設定する必要があります。spiders/scrapy_uranai.pyが定義するpythonファイルになります。
まずは全貌です。
import scrapy
from uranai.items import UranaiItem
class ScrapyUranaiSpider(scrapy.Spider):
name = 'scrapy_uranai'
allowed_domains = ['fortune.yahoo.co.jp']
start_urls = ['http://fortune.yahoo.co.jp/12astro/libra']
def parse(self, response):
item = UranaiItem()
item["total_point"] = response.css("div.yftn12a-tt02 div p::text").extract_first()
print(item)spiderがアクセスするドメインやパスを指定しています。また、perseを設定することでスクレイピングしてきたHTMLのどの要素を取り出すかを指定できます。
例えば今回の場合、スクレイピングして取得したい要素(総合運)周辺のHTMLは以下のようになっています。
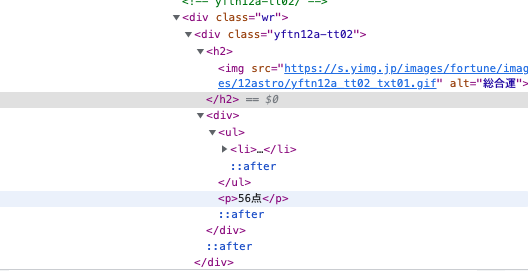
この中で取得したいのは"56点"(あんまりよくないな…)の部分になるので、その要素にたどり着くようにタグを追っていくのがperseの役割になります。
また、取得したデータは先ほど作成したUranaiItemに格納されるようにitemを指定しています。
レッツスクレイピング
準備が出来たので早速スクレイピングしてみましょう。下記コマンドで実行できます。
$ scrapy crawl scrapy_uranai実行すると様々なものが出力されますが、よくみてみると…
{'total_point': '56点'}ありました!総合運が取得できていますね!
itemsやperserを増やせば、その分一度に多くの要素を取り出すことができるので、どんどん挑戦してみると良いかもしれません。
ただし、大量のクローラを走らせてしまうとサーバに負荷を与えてしまいますので節度を守ってスクレイピングしましょう(SRE兼インフラエンジニアからのお願い)。
まとめ
スクレイピングめちゃくちゃ便利ですね!僕はこのScrapyを利用して星座占いの結果をLINE通知してみたりして遊んでいます。いろんなことに使用していきたいですね!
これまで名前だけはよく聞いていたスクレイピング、実際にやってみることで概要は説明できるくらいには理解できたかなと思います。
最近Pythonを書くことにハマりつつあるので、いろんな方法を用いたスクレイピングに挑戦していきたいですね!
ここまで読んでいただきありがとうございました!