【SRE】サービス信頼性の階層(Service Reliability Hierarchy)とはなんぞや
どもども、T-falのスチームアイロンを手にした結果QOLが爆上がりした僕です。
今年3月より所属しているSRE(Site Reliability Engineering)ユニットのリーダーを務めることになり、SRE組織とはどのような活動を行いどのようなバリューを求めていくべきかをよく考えさせられます。そんな中でSREユニットの指標として意識しておきたいと思ったのが"サービス信頼性の階層"です。
本日は"サービス信頼性の階層"について下記Google大先輩の資料を参考に確認していきたいと思います。
https://sre.google/sre-book/part-III-practices/
そもそもサービス信頼性の階層とは
Googleの記事にある
システムがサービスとして機能するために必要な最も基本的な要件から、より高いレベルの機能まで、サービスの健全性を特徴付けることができます。
https://sre.google/sre-book/part-III-practices/
この特徴を階層形式で表したものがサービス信頼性の階層と言えそうです。
ざっくり図で表すと下記のようになるようです。
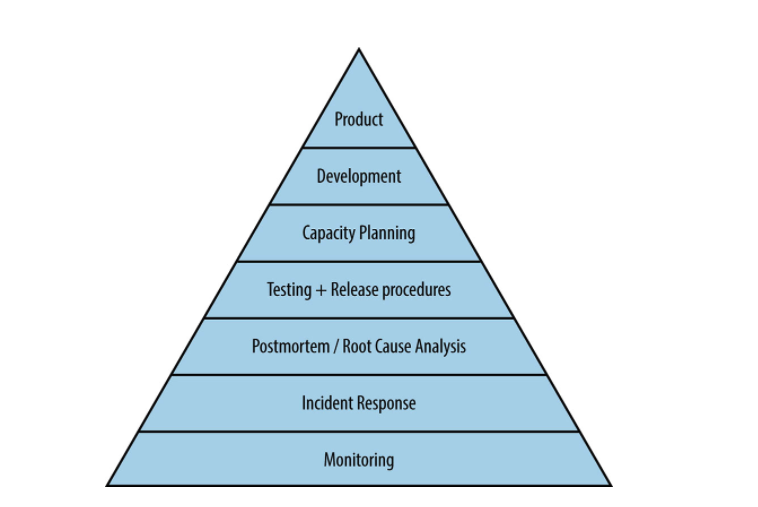
次に、それぞれの階層について具体的に確認してみましょう。
Monitoring
これは簡単な話で、いわゆる監視設定が行われているかという点だと思います。
大切なのは慎重に設計された監視インフラで監視を行なっているかどうかという点でしょうか。ユーザーが気付くよりも早く開発者がエラーに気づけるかどうかがプロダクトの信頼性を左右します。
そもそも監視設定を行なっていない場合は信頼性を図る指標が存在しないということになるわけですから、Monitoringは最も基本的な階層にふさわしいと思います。
Incident Response
直訳すると"インシデント対応"となります。
何か致命的な問題が発生した時、エンジニアによるオンコール対応が必要となります。
しかし、どのようなフローで一次対応を開始するのか、どれくらい原因特定の知見を持つエンジニアなのか、どのような方法で対応するのか、どのレベルまでの修復を期待するのか、などインシデント発生時におけるオンコール対応にはあらかじめ把握しておくべき要素がいくつもあります。
また、こちらもGoogle記事の内容ですが、
何が悪いのかを理解することが最初のステップです。効果的なトラブルシューティングで構造化されたアプローチを提供します。
https://sre.google/sre-book/part-III-practices/
こちらは非常に重要な一文だと思います。特に、構造化されたアプローチが提供されているかどうかでオンコール対応に関するハードルはかなり違ってくると思います。
インシデント発生時の対応体制の構築は、プロダクト信頼性に大きな恩恵をもたらすのでSRE組織が率先して行うべきものだと思います。
Postmortem and Root-Cause Analysis
インシデントに対する一次対応が完了したら、根本原因の分析が必要となります。
この根本分析こそ非常に大切なフェーズとなるわけですが、注意したいのは"誰かを非難するフェーズではない"ということです。
対応を総合的にみた結果、そもそも根本的な原因はなんだったのか、対応として何がうまくいったか、あるいは何がうまくいかなかったのか、これらをドキュメント化して残すことでインシデントから学びを得ることできます。いわゆるポストモーテムです。
その後の本番インシデント対応やシステムの改修に大いに貢献する知見として積み上げられる仕組みを作ることも、SREとしての責務なのだと思います。
Testing
根本的な原因が判明したら、修正の上テストを行う必要があります。
テストスイートは、ソフトウェアが本番環境にリリースされる前に特定のクラスのエラーを発生させていないことを保証します。
https://sre.google/sre-book/part-III-practices/
上記の内容からもあるとおり、本番環境に行くまでにどのようにして類似するインシデントを予防していくか検討しておくことが大切です。
Capacity Planning
少し流れが変わりますが、次にCapacity Planningについて確認していきます。
日本語では"用量計画"と表現されています。これは特にインフラストラクチャに関して注意しておくべき項目であるように思います。
予想されるリクエスト数から負荷分散をどのように行うか、構築したインフラ容量をどのように使用していくかなどの計画を立てることが、信頼性の担保には欠かせません。
これは上記の記事から脱した個人的見解ですが、負荷分散にとどまらずマシンスペック、料金設計などもこのキャパシティプランニングに含めて意識しておくべきポイントだと思います。
Development
Googleの記事ではGoogleにおける様々な取り組みを具体的に提示していますが、要するにこれまでの階層の知見を元に修正ではなくさらなるプロダクトの発展を行なっていく階層がここに当たると思います。
記事によれば
サイト信頼性エンジニアリングに対するGoogleのアプローチの重要な側面の1つは、組織内で大規模なシステム設計とソフトウェアエンジニアリングの重要な作業を行うことです。
https://sre.google/sre-book/part-III-practices/
とあります。組織内にSRE文化を醸成するにはSRE組織を内包する必要があると言うのは僕も常日頃感じているところではあります。
実際に自身の所属するユニットでも、同一手順の修正対応で後手に回るのではなく更に良い検知システムを構築できないかなどはよく検討されているところです。
Product
やっと最上位の階層です。
これらの階層を踏まえることで信頼性の高いプロダクトをユーザーに提供することができます。あるいは"プロダクトの信頼性を説明できる状態"に昇華できると言っても良いかもしれません。
このようにサービスの信頼性をどのように構築していくか、そのプロセスを基本的な部分から設計したものがサービス信頼性の階層と言えるでしょう。
最後に
今回はサービス信頼性の階層について各階層をざっくりと説明してました。もちろん各階層にはより深い意味があり、議論すべきポイントも存在するでしょう。
しかし、大きな指標が何もない状態で"SREとは"について議論しても答えはなかなか出ないように思います。このようにベースとなる骨組みを共通認識としているかどうかがSRE組織における議論をより円滑に進めると僕は思います。
他にもGoogleにおけるSREの知見は非常に沢山ありますので、ベースの知識とした上で実用するためにどのようにアレンジし最適化していくかを常に考えていこうと思います。
最後まで読んでいただきありがとうございました!
本日のおすすめ